




Accelerating AI Inference Workflows with the Atomic Inference Boilerplate
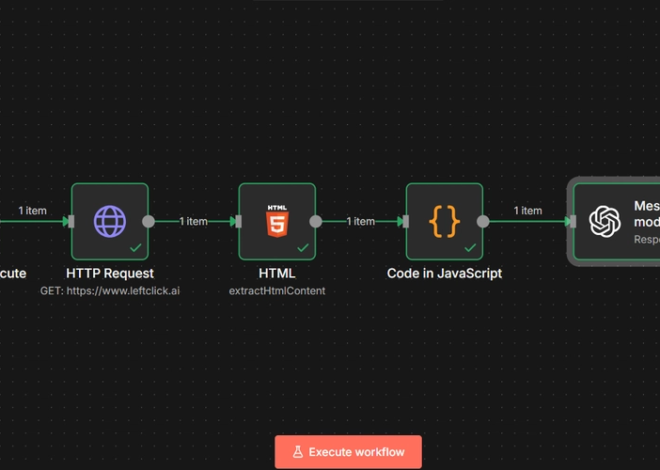
An opinionated foundation for reliable, composable LLM inference Large language model (LLM) applications grow complex fast. Prompt logic, schema validation, multi-provider setups, and execution patterns become scattered. What if you could standardize how individual inference steps are written, validated, and executed — leaving orchestration, pipelines, and workflows to higher-level layers? That’s the problem the atomic-inference-boilerplate […]
5 mins read